Visualizing datasets, storytelling and Tableau
ANLY-503: Advanced Data Visualization
The msleep dataset

|

|
Mammals sleeping data, available as ggplot2::msleep
Rows: 83
Columns: 11
$ name <chr> "Cheetah", "Owl monkey", "Mountain beaver", "Greater shor…
$ genus <chr> "Acinonyx", "Aotus", "Aplodontia", "Blarina", "Bos", "Bra…
$ vore <chr> "carni", "omni", "herbi", "omni", "herbi", "herbi", "carn…
$ order <chr> "Carnivora", "Primates", "Rodentia", "Soricomorpha", "Art…
$ conservation <chr> "lc", NA, "nt", "lc", "domesticated", NA, "vu", NA, "dome…
$ sleep_total <dbl> 12.1, 17.0, 14.4, 14.9, 4.0, 14.4, 8.7, 7.0, 10.1, 3.0, 5…
$ sleep_rem <dbl> NA, 1.8, 2.4, 2.3, 0.7, 2.2, 1.4, NA, 2.9, NA, 0.6, 0.8, …
$ sleep_cycle <dbl> NA, NA, NA, 0.1333333, 0.6666667, 0.7666667, 0.3833333, N…
$ awake <dbl> 11.9, 7.0, 9.6, 9.1, 20.0, 9.6, 15.3, 17.0, 13.9, 21.0, 1…
$ brainwt <dbl> NA, 0.01550, NA, 0.00029, 0.42300, NA, NA, NA, 0.07000, 0…
$ bodywt <dbl> 50.000, 0.480, 1.350, 0.019, 600.000, 3.850, 20.490, 0.04…Not very useful, since we can’t see much information
The msleep data

The msleep data
We can also look as how correlated the numerical variables are to each other using a correlation heatmap

The msleep data
We can also look at whether the data meets expectations, or are their “outliers” or potential issues in particular observations

A closer look at missing data patterns

This visualization provides both missing data patterns and summary statistics about the missing data
A closer look at missing data patterns
The naniar package by Nicholas Tierney provides more detailed looks at missing data patterns


This is a clever use of a standard visualization where the red dots show the values of one variable when the other variable is missing. This can show
- particular patterns in missingness, or a lack of pattern ✅
Missing value correlations

UpSet plots
The UpSet plot was originally developed at Harvard in 2014.
The main purpose was to solve the problem of set visualizations when you have more than one set (so an extension of Venn Diagrams), in an intuitive manner
It tries to solve the problem created by the following visualization looking at the intersection of 6 sets
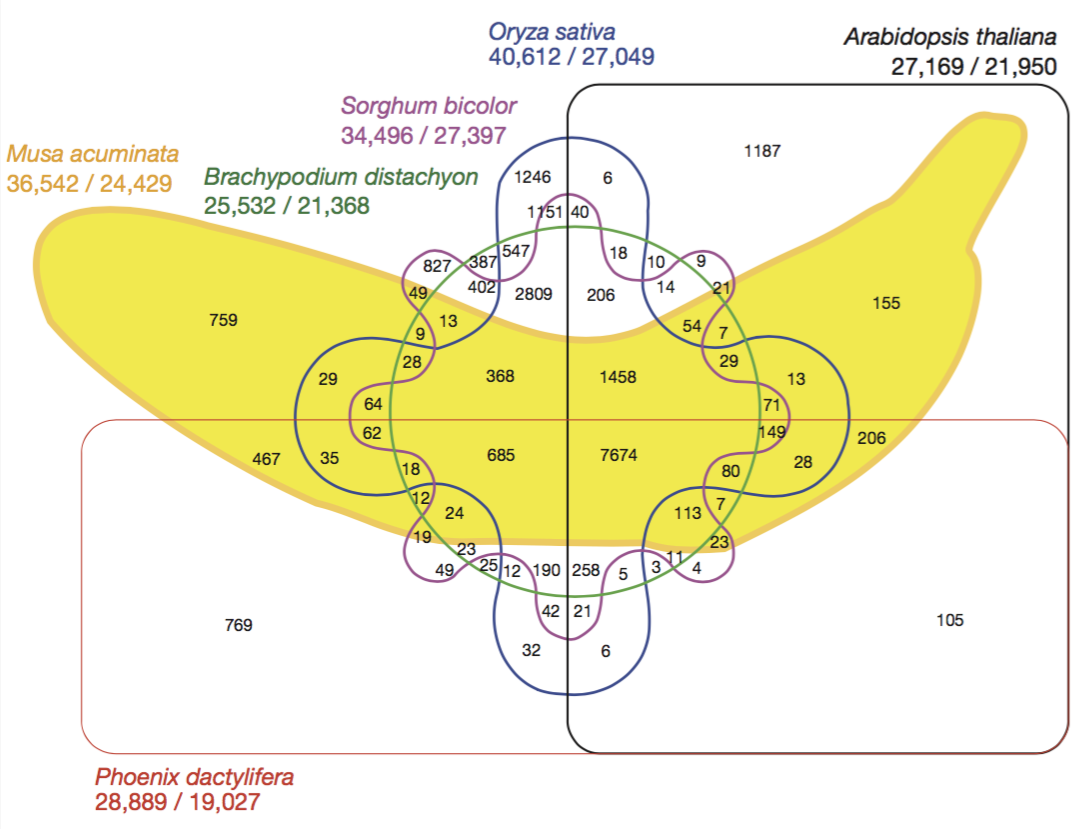
Example

UpSet plots
Let’s look at this from a missing data perspective. Each “set” is the missing/non-missing annotation of each variable in a data set, and we’re interested in when the missing data co-occur.

- The left barplot gives the number of missing data for each variable (here showing the top 5)
- The “barbells” show the different co-occurrence patterns
- The top barplot gives the frequencies of each co-occurrence pattern
UpSet plots (R)
Using the UpSetR package


UpSet plots (Python)
Code
vore sleep_rem brainwt conservation sleep_cycle
False False False False False 20
True 9
True False 9
True 5
True False False 1
True 10
True False 1
True 1
True False False True 5
True True 3
True False True 7
True True 5
True False False False True 2
True False 1
True 2
True True True True 2
dtype: int64
Humans are wired for stories

Stories are a survival mechanism across generations
Data storytelling is essential
Often, your jobs as a data-scientist is to be an effective communicator
There is more to communication than numbers on a paper
Stories are up to 22 times more memorable than facts alone
When in doubt, tell stories

Data stories appear to be most effective when they have constrained interaction at various checkpoints within a narrative, allowing the user to explore the data without veering too far from the intended narrative.
What is data story telling?

Components of a data story

Story linearity
- Whether driven by time or logic, stories are typically is linear
Every story has a beginning, middle and end



Traditional vs data stories

Common visual narrative Genres

Standard Info-graphics
- An infographic is a collection of imagery, data visualizations, and minimal text that gives an easy-to-understand overview of a topic.
![]()

Data Info-graphics
- Data infographic are info-graphics that relies entirely or mostly on numbers to tell the story. This often includes data visualization, such as charts and graphs, but not always.
![]()

Research posters
- Even research poster construction requires a narrative flow!!
![]()

Scientific papers structure

Developing knowledge content

Primary communication tools

Engagement levels-1

Engagement levels-2

Storytelling tips

Author vs reader driven

Break
Lets take a 10 minute break before moving onto the lab.
